How do you visualize 87,000 links between Jewish texts?
The answer, at least when one is working on an ordinary iMac, is very slowly.
The better–by which I mean more accurate and productive–question is: How do you meaningfully visualize the relationships between over 100,000 individual sections of Jewish literature as encoded into Sefaria, a Living Library of Jewish Texts?
The key term for me is meaningfully – working at this scale means I have to get out of my network comfort zone and move from thinking about the individual nodes and their ego networks towards a holistic appreciation of the network as a structural entity. I’m not able to do that quite yet, at least not in this post. This is the first post in a series of explorations – what kinds of graphs can I make with this information and what information can I get from it (or read into it)?
This project and, perforce, this series is another side of the research questions that I’m currently grappling with – how do the formal attributes of digital adaptations affect the positions we take towards texts? And how do they reorganize the way we perceive, think about and feel for/with/about texts?
Because this is Ludic Analytics, the space where my motto seems to be “graph first, ask questions later,” it seemed an ideal place to speculate about what massive visualizations can do for me.
Let’s begin with a brief overview of Sefaria. Sefaria is a comparatively new website (launched in 2013) that aims to collect all the currently out-of-copyright Jewish texts and not only provide access to them through a deceptively simple interface, but also crowd-source the translations for each text and the links between them. For example, the first verse of Genesis (which we will return to later) is quoted in the Talmud (one link for every page that quotes it), has numerous commentaries written about it (another link for every commentary), is occasionally referenced in the legal codes and so on. Here’s a screenshot of the verse in Sefaria.
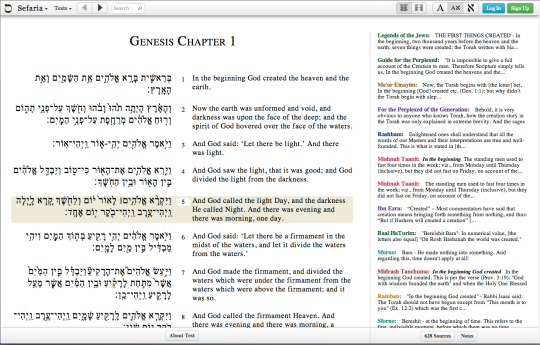
Sefaria Screenshot
You can see, along the sides, all the different texts that reference this one and, of course, if you visit the website, you can click through them and follow a networked thread of commentaries like a narrative. Or like a series of TVTropes articles.
Sefaria did not invent the hyperlinked page of Rabbinic text. Printed versions of the Bible and the Babylonian Talmud and just about every other text here–dating all the way back to the early incunabula–use certain print conventions to indicate links between texts and commentaries, quotations and their sources. The Talmud developed the most intricate page by far, but the use of printing conventions such as font, layout and formal organization to show the reader which texts are connected to which and how is visible in just about every text here.
What Sefaria does (along with any number of other intriguing things that are not the topic of this post) is turns print links into hyperlinks and provides a webpage (rather than a print page) that showcases the interconnectedness of the literature. Each webpage is a map of every other text in Sefaria that connects to the section in question, provided that someone got around to including that connection. Thus we see both the beauty and the peril of crowdsourcing.
So the 87,000 links to over 100,000 nodes that I was given (thank you @SefariaProject!) are not exactly a reflection of over 2,000 years of Jewish literature as such, but a reflection of how far Sefaria has come in crowdsourcing a giant digital database of those 2,000 years and how they relate to one another. That caveat is important and it constrains any giant, sweeping conclusions about this corpus (not that I, as a responsible investigator, should be making giant sweeping conclusions after spending all of two weeks Gephi-wrangling). Having said that, the visualizations are not only a reflection of Sefaria’s growth, but also a way to reflect on the process of building this kind of crowd-sourced knowledge.
But before subsequent posts that analyze and reflect and question can be written, this post in all its multicolored glory must be completed.
To return to my very first question, how do you visualize 87,000 links?
Like this:

Figure 1
This is Sefaria. Or a cell under a microscope. It’s hard to tell. Here’s the real information you need. This graph was made using the Gephi plugin for OpenOrd graphing, a force directed layout optimized for large datasets.* The colors signify the type of text. Here’s the breakdown.
Blue – Biblical texts and commentaries on them (with the exception of Rashi). Each node is a verse or the commentary by one author on that verse.
Green – Rashi’s commentaries. Each node is a single comment on a section
Pink – The Gemara. Each node is a single section of a page.
(Note – these first 3 make up 87% of the nodes in this graph. Rashi actually has the highest number of nodes, but none of them have very many connections)
Red – Codes of Law. Each node is a single sub-section.
Purple – The Mishnah. Each node is a single Mishnah.
Orange – Other (Mysticism, Mussar, etc.)
The graph, at least as far as we can see in this image, is made up almost entirely of blue and pink nodes and edges. So the majority of connections that Sefaria has recorded occur between Biblical verses and the commentaries, the Gemara and Biblical references and the Gemara referencing itself.
Size corresponds to degree – the more connections a single node has, the larger it is. The largest blue node is the first verse of Genesis.
On the one hand, there is an incredible amount of information embedded in this graph. On the other hand, it’s almost impossible to read. There are some interesting things going on with the patterns of blue nodes clustering around pink nodes (the biblical quotations and their commentaries circling around the pages of the Gemara that reference them, perhaps?), but there are so many nodes that it’s hard to tell.
There’s also a ton of information not encoded into the graph. Proximity is the biggest one. There is absolutely nothing linking the first and second verses of Genesis, for example. Arguably, linear texts should connect sequentially and yet the data set I used does not encode that information. So this data set conveys exclusively links across books without acknowledging the order of sections within a given book.
But, as I told my students this quarter, the purpose of a model is not to convey all the information encoded in the original, but to convey a subset that makes the original easier to manage. This model, then, is not a model of proximity, It is purely a model of reference. Let’s see what happens when we look at it another way.

Figure 2
Gephi does not come with a spatial layout function, but there are user-created plugins to do this kind of work. This is the same dataset as above, except arranged on a Cartesian plane with the X axis corresponding to In Degree (how many nodes have that node as a target for their interactions) and the Y axis corresponding to Out Degree (how many nodes have that node as a source for their interactions).** The size corresponds to a node’s Betweenness Centrality – if I were to try and reach several different nodes by traveling along the edges, the bigger nodes are the nodes I am more likely to pass through to get from one node to another.
The outlier, obviously, is Genesis 1:1. It has far and away the most connections and, especially based on its height, is the source for the greatest number of interactions. (That probably means that, out of all the information Sefaria has collected so far, the first verse of Genesis has the most commentaries written about it). It’s not the most quoted verse in Sefaria, that distinction belongs to Exodus 12:2 (the commandment to sanctify the new moon, for those who are wondering). Second place goes to Deuteronomy 24:1 (the laws of divorce) and third goes to Leviticus 23:40 (the law of waving palm branches on Succot).*** So for this data set, most quoted probably signifies most often quoted in the legal codes in order to explicate matters of law. And while the commentaries tend to focus on some verses more than others, the codes seem to rely almost exclusively on a specific subset of verses that are related to the practices of mitzvoth. I think I was aware of this beforehand, but the starkness of the difference between Genesis 1:1 and Exodus 12:2 is still surprising and striking.
Working with Betweenness Centrality as a measure of size was interesting because it pointed towards these bridge texts – statistically speaking, Genesis 1:1 is the Kevin Bacon of Sefaria. You are more likely to be within 6 degrees of it than anything else.
There are a few other interesting observations I can make from this graph. The first is that the Gemara is ranged primarily along the Y axis, suggesting that the pages of the Gemara are more rarely the target for interactions (which is to say that they are not often quoted elsewhere in Sefaria) ,but more often the sources and, as such, quote other texts often and have substantial commentaries written about them. Because one of the texts quoted on a page of Gemara is often another page of Gemara, you do see pages along the X axis, but none range as far along the X axis as along the Y. While there are texts that are often the target of interactions, the Gemara is, overall, the source.
This is in contrast to the Biblical sections, which occupy the further portions of the X axis (and all the outliers are verses from the five books of the Torah). So the graph, overall, seems to be shading from pink to blue.
Which brings me to another limitation in my approach. Up until now, I have been thinking about these texts as they exist in groups, using that as a substitute for the individual nodes that would ordinarily be the topic of conversation. So what happens when I create a version of the graph that uses color to convey a different kind of meaning and no longer distinguishes between types of texts?

Figure 3
Sefaria, taste the rainbow.
In this graph, color no longer signifies the kind of text, but the text’s degree centrality. The closer to the purple end of the rainbow, the higher number of connection the node has. Unsurprisingly, Genesis 1:1 is the only purple node.
It’s interesting to note that the highly connected nodes on the right of the graph are all connected to a large number of lower level nodes. There are no connections between the greens and yellows near the top of the page and the blues down on the right. Why is there such a distinction between nodes that reference and nodes that are referenced? Why is the upper right quadrant so entirely empty? Does this say something about the organization of the texts or about the kinds of information that the crowd at large has gotten around to encoding? Or is it actually a reflection of the corpus – texts that cite often are not cited in turn unless they are in the first book of the Torah?
If you have any questions, thoughts, explanations, ideas for further research with this data set or these tools, suggestions for getting the most out of Gephi, please leave your comments below.
Coming soon (more or less): What happens when we look at connections on the scale of entire books rather than individual verses?
Bonus Graph: A Circular graph with Genesis 1:1 as the sun in what looks like a heliocentric solar system. Why? Well, it seemed appropriate.

One note on this graph. You can see the tiny rim of green all around the right edge – those are the tiny nodes that represent Rashi’s commentaries and make up more than 1/3 of all the nodes in the graph. The inner rings, at least what we can see of them, tend towards Biblical verses and their commentaries. The Gemara is almost all on the outside. Of course, those distances are artifacts of deliberately placing Genesis 1:1 at the center, but they are interesting nonetheless.
—
*Force directed, to provide a very brief summary, means that the graph is designed to create clusters by keeping all the edges as close to the same length as possible. Usually it works by treating edges as attractive forces that pull nodes together and the nodes themselves as electrically charged particles that repulse one another.
**At least in this data set, the source is the text under discussion, so if one were to look at the connection between Genesis 1:1 and Rashi’s commentary on Genesis 1:1, the Biblical verse is the source and the commentary the target. Conversely, if one were looking at a quotation from Genesis in a page of the Gemara, the page of Gemara would be the source and the verse in Genesis the target.
***Based on further explorations of the data set according to less fine-grained divisions, I am convinced that anything having to do with the holiday of Succot is an outlier in this dataset. More on that in another post.

Comments on: "Sefaria in Gephi: Seeing Links in Jewish Literature" (12)
Is there a bias towards Genesis because people are progressing from start to end in the various commentators? That is, has every Sefaria work-in-progress gotten to Genesis 1:1, but not to Chronicles?
Also, regarding your observation about the Gemara citing other texts but not vice-versa — in general, wouldn’t you have the issue of the “arrow of time” here? It might be interesting to see a stratified graph, with Tanakh on the bottom (with Genesis 1:1 on the far right and the end of Divrei ha-Yamim on the far left), then a band of Mishna, Gemara (again in tractate order from right to left), then the meforshim, with the Y-axis representing the year in which the corpus was (estimated to be) written.
Still, cool project!
That’s a really interesting idea to use the arrow of time – I thought about it and couldn’t think of a way to do it quickly so I left it aside for this round of results. But the approach you suggest of dividing first into era and then organzing the timeline within each era could work nicely.
Thank you for taking the time to read and respond!
This is beautiful work and very interesting! Can’t wait to see more…
Sefaria’s dataset is heavily biased for “what we have” and not “everything there is”. We have many more sources on Genesis 1:1, but we also use that page to demo the project the most, so it’s gotten a lot more attention than some other sources.
There are some limited areas where this is less true. Almost all of the connections between Talmud Bavil and Tanakh for example form a more complete set, thanks to annotations in Wikisource Bavli (and extract to Sefaria from a volunteer engineer). That might be a good place to limit some views.
We’re also very close to releasing some more general code for finding citations in hebrew texts. Once we have this we’ll be able extract a lot of latent links. This should give some much more evenly distributed samples, especially in the full Torah commentaries that we have.
Thank you! And thank you for the data that made this possible!
Yeah, I noticed Genesis 1:1 on the front page and it’s the first thing I clicked through when I first heard about your site. (My chavruta and I appreciate it, by the way.)
Knowing that the Tanakh – Bavli connections are extracted is helpful; I may take a look at narrowing the data set to those next. You also mentioned on Twitter that you can do less fine-grained divisions between data points. I would be really interested in seeing what this dataset looks like when divided by book rather than page/verse. And I’m definitely looking forward to seeing the citation code and its results.
I’d love to see somebody create a PageRank-like metric for Jewish sources for halachically related searches. I would think that this would be a great indication of the authority of sources. Of course, it wouldn’t really work unless there were a critical mass of halachic works encoded with links. My wife sent me a link to this page because she discovered it after we had discussed my Jewish PageRank idea.
Could you attempt visualisations of only the “quoted/cited” and not the “commented on” links? The latter are often uninteresting because they tend to follow texts linearly and are motivated to be relatively complete in their coverage of a portion of text.
Separately, because our nodes correspond to discrete sources with internal structure, as you note, could we look at the links between (no source-internal links, though we could choose to look at each Masechet of talmud as a source in one such visualisation) sources by representing each source as the edge of a polygon (with detached edges, perhaps), along the lines of circular graphs. Then all arcs will stretch from one edge to another. One could allow contiguous text to form adjacent segments of the line, this has the potential to produce a very cluttered graph. But you could see the broad relationships between works, and segments of works, in this sort of an graph.
HI,
Very interesting work!!! It looks like a scale free network to me. Meaning that if some information is missing it doesn’t matter because the shape will be the same if you use all the data. You can run couple analysis to identify some features. Motif detection, in order to evaluate if some patterns are overepresented (FANMOD) and secondly a community detection. The latter might show a clustering of the graph by topics…
I have been thinking about this kind of project from a slightly different angle.
sefaria is both great and very limite – as others have pointed out.
you might be interested in measurement of legal complexity (see here http://computationallegalstudies.com/2010/08/02/measuring-the-complexity-of-the-law-the-united-states-code/ and here http://www.wired.com/2014/06/scienceblogs0602law/
for applications to the french code see the archiv pdf’s
Click to access 1204.6284.pdf
Click to access 1201.1259.pdf
and a more comprehensive paper at
http://202.154.59.182/mfile/files/Law/Approaches%20to%20Legal%20Ontologies%3B%20Theories,%20Domains,%20Methodologies/Chapter%207%20A%20Complex-System%20Approach%3B%20Legal%20Knowledge,%20Ontology,%20Information%20and%20Networks.pdf.
for a neat ttime-lapse see https://www.youtube.com/watch?v=38mmdbdaKFY
see also
Click to access 2007bourciermazzegaicail.pdf
would be delighted to join the efforts
Amos
[…] post is distinct from the previous ones, which can be found here: part 1, part 2, and part 3, in that I’m finally going to move away from looking at the images themselves […]
[…] more informative. Links between texts open up opportunities for richer and broader study, and for analysis of the whole network of textual […]
Hey Liz. Trying to get hold of you to ask you something on this
Tried FB and tweeting. Can you send me an email ad please
Thank you
Hi, sorry about that!
I tend not to see Facebook messages from people I don’t already know, but now that I know to look for you, I’ll respond there.
Thanks!